|
DeepSeek 的模型 上述三个动态可以帮助我们理解 DeepSeek 近期发布的模型。大约一个月前,DeepSeek 发布了一个名为“DeepSeek-V3”的模型,这是一个纯粹的预训练模型——即上述第三点中描述的第一阶段。上周,他们又发布了“R1”,在 V3 的基础上增加了第二阶段。从外部无法完全了解这些模型的全部信息,但以下是我对这两次发布的最佳理解。 DeepSeek-V3 实际上是真正的创新所在,一个月前就应该引起人们的注意(我们当然注意到了)。作为一款预训练模型,它在某些重要任务上的表现似乎已接近美国最先进的模型水平,但训练成本却大大降低(不过,我们发现,特别是 Claude 3.5 Sonnet 在某些其他关键任务上,例如实际编程方面,仍然明显更胜一筹)。DeepSeek 团队通过一些真正令人印象深刻的创新实现了这一点,这些创新主要集中在工程效率方面。特别是在名为“键值缓存 (Key-Value cache)”的某一方面管理以及推动“混合专家 (mixture of experts)”方法更进一步的应用上,取得了创新性的改进。 然而,有必要进行更深入的分析: DeepSeek 并未“以 600 万美元的成本实现了美国人工智能公司数十亿美元投入的效果”。我只能代表 Anthropic 发言,Claude 3.5 Sonnet 是一款中等规模的模型,训练成本为数千万美元(我不会给出确切数字)。此外,3.5 Sonnet 的训练方式与任何规模更大或成本更高的模型无关(与某些传言相反)。Sonnet 的训练是在 9-12 个月前进行的,而 DeepSeek 的模型是在 11 月/12 月训练的,但 Sonnet 在许多内部和外部评估中仍然显著领先。因此,我认为一个公正的说法是:“DeepSeek 生产出了一款性能接近美国 7-10 个月前模型的模型,成本大幅降低(但远未达到人们所说的比例)”。 如果成本曲线的历史下降趋势约为每年 4 倍,这意味着在正常的商业进程中——在 2023 年和 2024 年发生的历史成本下降等正常趋势下——我们预计现在会出现一款比 3.5 Sonnet/GPT-4o 便宜 3-4 倍的模型。
由于 DeepSeek-V3 的性能不如那些美国前沿模型——假设在规模曲线上落后约 2 倍,我认为这对于 DeepSeek-V3 来说已经相当慷慨了——这意味着,如果 DeepSeek-V3 的训练成本比美国一年前开发的现有模型低约 8 倍,那将是完全正常、完全符合“趋势”的。我不会给出具体数字,但从前一点可以清楚地看出,即使你完全相信 DeepSeek 宣称的训练成本,他们的表现充其量也只是符合趋势,甚至可能还达不到。例如,这远不如最初的 GPT-4 到 Claude 3.5 Sonnet 的推理价格差异(10 倍),而 3.5 Sonnet 是一款比 GPT-4 更出色的模型。
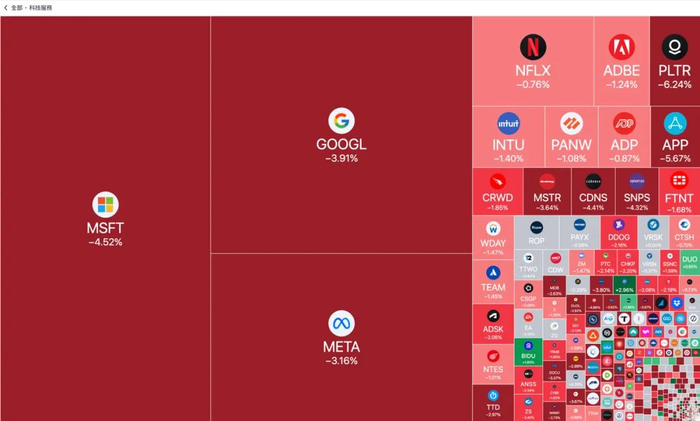
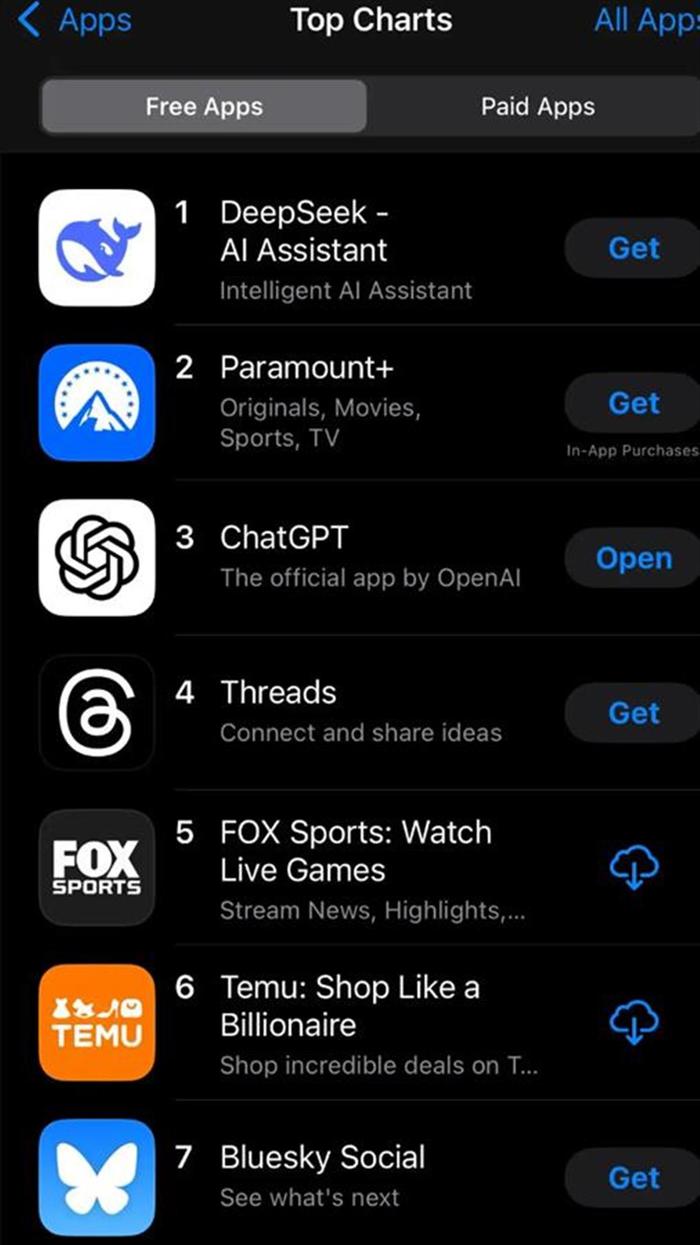
总而言之,DeepSeek-V3 并非一项独特的突破,也并非从根本上改变了大型语言模型 (LLM) 的经济性;它只是持续成本降低曲线上一个预期的点。这次的不同之处在于,第一个展示预期成本降低的公司是中国公司。这在以前从未发生过,并且具有地缘政治意义。然而,美国公司很快也会效仿——而且他们不会通过复制 DeepSeek 来做到这一点,而是因为他们也在实现通常的成本降低趋势。 DeepSeek 和美国人工智能公司都比以往拥有更多的资金和更多的芯片来训练其明星模型。额外的芯片用于研发支持模型背后的理念,有时也用于训练尚未准备就绪(或需要多次尝试才能成功)的更大模型。有报道称——我们无法确定其真实性——DeepSeek 实际上拥有 50,000 块 Hopper 架构的芯片,我猜这与美国主要人工智能公司拥有的芯片数量在 2-3 倍的差距内(例如,比 xAI 的 “Colossus” 集群少 2-3 倍)。这 50,000 块 Hopper 芯片的成本约为 10 亿美元。因此,DeepSeek 作为一家公司的总支出(与训练单个模型的支出不同)与美国人工智能实验室的支出并没有天壤之别。 值得注意的是,“规模曲线”分析有些过于简化,因为模型在某种程度上是存在差异的,并且各有优缺点;规模曲线数字是一个粗略的平均值,忽略了许多细节。我只能谈谈 Anthropic 的模型,但正如我上面暗示的那样,Claude 在编程和与人进行良好设计的互动风格方面非常出色(很多人用它来寻求个人建议或支持)。在这些以及一些额外的任务上,DeepSeek 完全无法与之相提并论。这些因素在规模数字中并未体现出来。 上周发布的 R1 模型引发了公众的广泛关注(包括英伟达股价下跌约 17%),但从创新或工程角度来看,它远不如 V3 有趣。R1 模型增加了第二阶段的训练——强化学习,在前一节的第 3 点中对此进行了描述——并且基本上复制了 OpenAI 在 o1 模型中所做的工作(他们似乎处于相似的规模,结果也相似)。然而,由于我们正处于规模曲线的早期阶段,只要它们从强大的预训练模型起步,多家公司就有可能生产出这种类型的模型。在 V3 的基础上生产 R1 模型的成本可能非常低廉。因此,我们正处于一个有趣的“交叉点”,暂时会出现多家公司都能生产出优秀的推理模型的情况。但随着所有公司在这种模型的规模曲线上进一步前进,这种情况将迅速消失。
| 






























 发表于 2025-1-29 10:57
发表于 2025-1-29 10:57
 提升卡
提升卡 置顶卡
置顶卡 沉默卡
沉默卡 喧嚣卡
喧嚣卡 变色卡
变色卡 千斤顶
千斤顶 显身卡
显身卡 楼主
楼主

































 发表于 2025-1-29 15:20
发表于 2025-1-29 15:20